
 85
85 0
0在当今数字时代,数据已成为推动各行各业发展的新型生产要素和核心动力,其重要性日益显著。 尤其是近些年来,以大模型为代表的新一轮人工智能浪潮迅速席卷全球,为各行各业带来了前所未有的变革。由于大模型通常 ...
|
在当今数字时代,数据已成为推动各行各业发展的新型生产要素和核心动力,其重要性日益显著。 尤其是近些年来,以大模型为代表的新一轮人工智能浪潮迅速席卷全球,为各行各业带来了前所未有的变革。由于大模型通常依托大规模数据进行训练,因而随着模型规模的持续扩大,对数据存储的要求也持续提高。
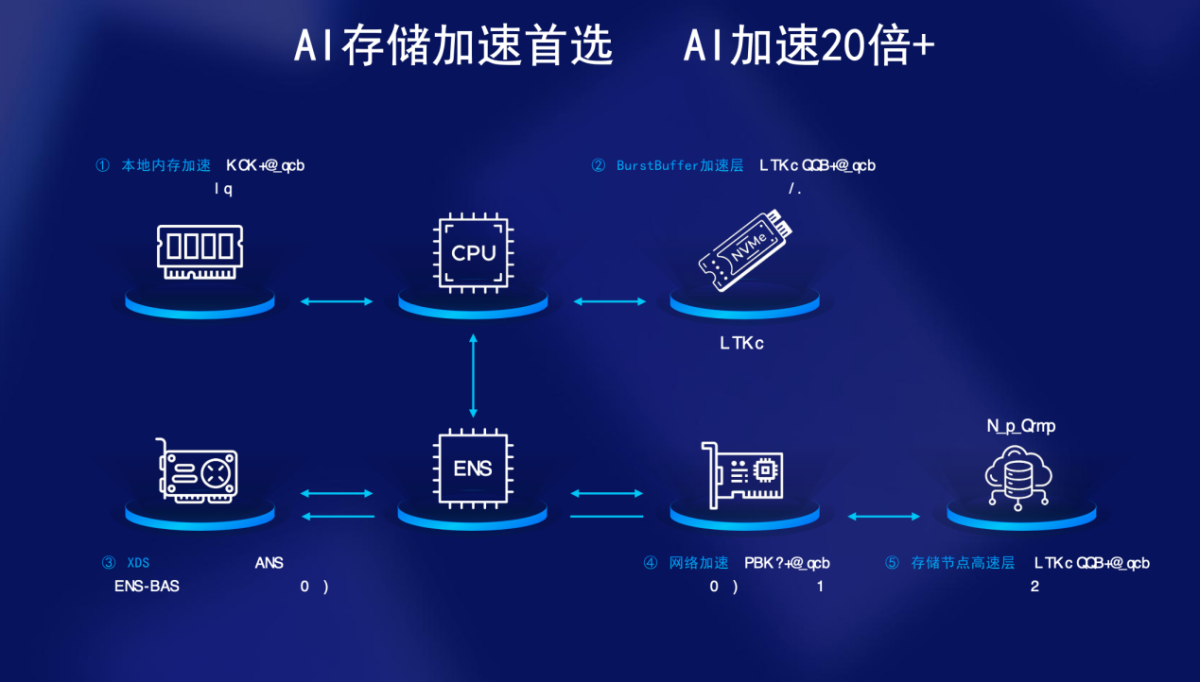
在数据存储领域,曙光存储是颇具竞争力的参与者。据赛迪发布的《2024中国分布式存储市场研究报告》披露,曙光存储位居中国AI存储市场第一。国家信息中心随后发布的《智能算力产业发展白皮书》,也重磅推介曙光存储面向推出的“智存”产品,点赞其面向人工智能场景的数据存储能力。 日前,天极网采访到中科曙光存储产品事业部运营总监石静,她分享了曙光存储通过一套“加速”组合拳,应对AI数据存储需求的成功经验。 大模型快速崛起,存储重要性日渐凸显 众所周知,人工智能的发展依赖于算力、算法和数据。在石静看来,大模型热度的提升凸显了数据存储的产业价值。模型本身的质量直接关系到能否精准支持各行业未来的应用与发展。如果数据质量不佳,可能导致训练出的大模型产生误导性输出。因此,存储所承载的数据质量显得尤为关键,这也进一步提升了存储的地位。 反过来说,如果在大模型训练过程中忽视存储,也将会带来严重后果。一方面,随着算力的不断提升,如果存储速度无法匹配,将导致算力效率无法得到充分发挥。例如,投入了大量的GPU算力,如果存储处理不当,将会造成GPU的空载、空转或等待,从而无法为用户带来更多效率上的提升。另一方面,如果忽略掉存储,在一些数据的质量上,会产生偏差问题。总体来看,只有更多地关注数据存储和数据本身,才能确保大模型训练既迅速又高效,从而在即将到来的模型竞争中获得优势。 据介绍,在过去一年多的客户沟通中,曙光存储观察到需求的变化。最初,客户可能直接询问关于训练所需的存储容量,如200T或1PB。随着发展,客户开始关注如何使存储与特定硬件更高效地结合。而现在,客户更加注重存储如何与应用相结合,以提升模型训练的效果。 “这种转变反映出用户对存储的关注度从单纯的功能性需求向更加贴合实际应用需求的转变,这也是我们作为存储厂商所见证的行业变化。”石静说。 需要指出的是,相较于小模型,大模型在训练、推理及落地应用上对数据存储提出了新的要求。具体来看: 第一,存储性能。随着计算复杂性的增加,对存储性能的要求也达到了新的高度。无论是在大模型的训练还是推理过程中,存储都不能成为计算的瓶颈。例如,在将训练集导入到GPU缓存时,或者读取相关数据或定期写回存储进行Checkpoint时,都会涉及大量小文件的读、写和高通量数据的读写操作。与以前相比,现在对存储压力和需求都有了数量级的高要求。过去,3GB带宽的存储就能满足大多数应用,但现在可能需要几百GB。整个性能要求提升了数倍甚至数十倍,这就要求存储能够在大带宽时发挥极致性能,同时在高并发IOPS带宽发挥更高的性能。简单来说,存储必须足够快,才能与足够快的GPU或AI芯片相匹配。 第二,契合业务。除了要求存储越来越快之外,用户还希望存储能更加契合业务需求。在业务预处理或模型训练微调后,结合应用从通用大模型转向垂直大模型演进的过程中,需要一些个性化服务。这就需要存储能够结合应用进行针对性调优或定制开发,这也要求存储具有一定的可定制化能力。 第三,数据安全。对于存储来说,数据的可靠性至关重要。实际上,训练一个千亿级或百亿级的大模型可能需要半个月甚至一个月的时间。在这个过程中,如果存储发生一些灾难性的故障,将对整个训练造成致命影响。所以,数据的安全可靠性尤为关键。此外,企业在考虑如何保障数据安全时,也需要对数据进行分级访问管理,这要求存储系统具备管理审计、权限管理以及与用户账号管理结合的能力。从整体上确保数据的I/O通路安全可靠,数据不会被篡改且可追溯。 由此可见,大模型时代下的数据存储不仅要提供更好的性能表现,还要具备高度的灵活性和强大的安全保障机制。 ParaStor分布式全闪存储,为AI落地“提速” 随着通用人工智能渐行渐近,越来越多人形机器人进入到公众视野。2023年8月18日,智元机器人发布第一代通用型具身智能机器人—远征AI,以“半年造出人形机器人”的惊人速度震撼业内。 时隔一年之后,智元机器人更是一口气发布了“远征”与“灵犀”两大家族共计五款商用人形机器人新品,并宣布在交互服务、柔性智造、特种作业、科研教育及数据采集等场景开启商用量产。 事实上,智元机器人之所以能够实现产品的快速迭代,离不开曙光存储提供的智存产品——ParaStor分布式全闪存储的支撑,具体来看: 一、AI存储加速首选,AI加速20倍+ ParaStor分布式全闪存储采用业界首创五级加速方案,包括:本地内存加速、BurstBuffer加速层、XDS双栈兼容、网络加速,以及存储节点高速层,让数据无需等待。
本地内存加速。首先将计算节点自身的CPU对应内存资源利用起来。关键数据和需要训练的热点数据将被优先应用或缓存至CPU自身的内存中,将本地内存的响应时间降至纳秒级别,实现对热点数据的加速处理。 BurstBuffer加速层。进一步利用GPU服务器上的本地NVMe盘。这意味着,不必跨网络访问远程存储,只需将关键数据存储在计算节点本地的NVMe盘上,就可以避免大量的网络数据传输和远程存储访问。这种配置适合于存储和快速读取海量小文件,能够将读取性能提升数倍甚至十倍以上。 XDS双栈兼容,减少CPU中断。在传统模式下,GPU通过CPU进行协同再与存储交互,而现在则是让GPU直接访问存储,不仅减少了CPU本身的损耗,也缩短了整个I/O通路,并降低了延时。 网络加速(RDMA-Based)。在网络层,主要运用RDMA技术。无论是在InfiniBand网络还是在以太网中,RDMA或RoCE都能最大化利用网络带宽,为数据传输提供网络层的加速。 存储节点高速层(NVMe SSD-Based)。目前在AI应用中,NVMe全闪存被广泛采用。为了充分发挥全闪存的性能优势,ParaStor分布式全闪存储的存储层也进行了相应的优化和加速。 二、AI平台首选,全平台性能最优 在2024年6月,曙光存储对ParaStor分布式存储系统进行了全闪升级与技术优化,单节点最高带宽从130GB/s升级至150GB/s;IOPS性能也大幅提升,可达320万次;单流带宽也得到显著增强,现已达到10GB。
三、AI生态开放首选 无论是国外,还是国产的芯片架构,ParaStor分布式全闪存储都可以兼容,让数据在异构、异地、云上云下实现无障碍流动。 目前,ParaStor分布式全闪存储已在多个场景实现落地。举例来说,在大模型场景,曙光存储助力某科技大模型厂商加速模型开发训练,与传统SSD混闪文件存储相比,ParaStor分布式全闪存储分钟级写入3TB CKPT数据,整体训练效率提升50%以上;这里可以写移动智算中心、某自动驾驶客户。 可以说,ParaStor分布式全闪存储在多个行业场景中展现了强大的适应性和实用性,为AI的规模化应用打造坚实的数据底座。 写在最后: 值得一提的是,在近期举办的2024全球闪存峰会上。曙光存储凭借ParaStor分布式存储强大的性能优势,及在多个AI创新业务场景中的优秀实践,荣获2024年度闪存风云榜“2024年度AI与闪存融合应用创新奖”。
这不仅是对曙光存储在技术创新和应用实践方面的充分肯定,更凸显出该公司在AI数据存储市场上的实力。 可以预见的是,随着大模型技术的不断发展和数据存储需求的持续扩大,曙光存储将持续秉承“强者恒存”的产业精神,以先进存力及深厚的市场洞察力,引领数据存储产业不断取得新的突破,助力万千行业加速迈进智能时代。 文章来源:中关村在线 作者:yu |









 闽公网安备 35020302000xxx号
闽公网安备 35020302000xxx号