
 13
13 0
0人工智能大模型计算、高性能计算(HPC)以及数据中心等行业的迅猛发展,对计算机系统内存性能的需求日益提升。 江波龙此前于CFMS2024展出了一款基于Compute Express Link (CXL)技术的创新内存扩展设备——CXL 2 ...
|
人工智能大模型计算、高性能计算(HPC)以及数据中心等行业的迅猛发展,对计算机系统内存性能的需求日益提升。
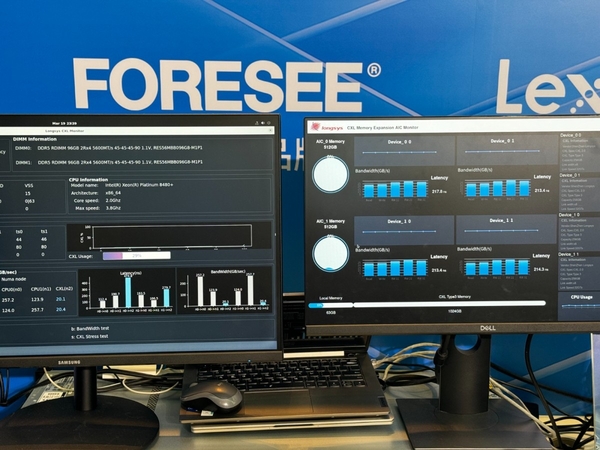
江波龙此前于CFMS2024展出了一款基于Compute Express Link (CXL)技术的创新内存扩展设备——CXL 2.0 AIC内存扩展卡。据了解,这款扩展卡采用非DRAM on-board封装设计,可兼容多种容量和规格的直插式内存条。它不仅支持CXL1.1标准,实现单个计算节点服务器线缆直连的直插式内存条扩展,还兼容CXL2.0标准,支持多个计算节点服务器集群与存储池线缆直连的直插式内存池化,从而满足多样化的应用场景需求。
全高全长的PCIe Add-in Card (AIC)封装为其带来更好的兼容性,扩展卡上配备了8个DIMM插槽,支持DDR4 RDIMM内存条,内存容量可扩展至512GB,同时通过MCIO高速接口支持PCIe 5.0 x16通道,理论带宽可达惊人的128GB/s。扩展卡与支持CXL规范的服务器主板通过MCIO线缆直连,从而为单个服务器和服务器集群提供大容量、高带宽、低延迟的扩展内存。
在CFMS2024展会现场,江波龙展位详尽展示了CXL AIC内存扩展卡的各项特性和竞争优势。
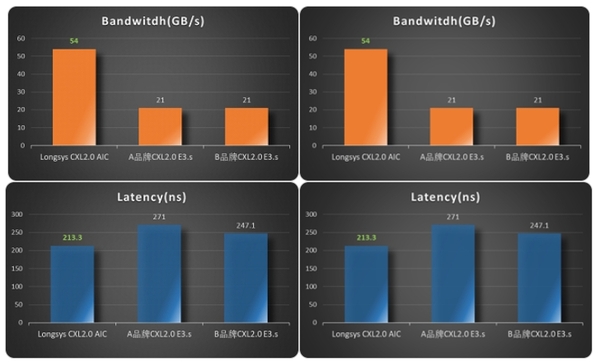
性能方面,江波龙CXL 2.0 AIC内存扩展卡实测性能远超业界现有DRAM on-board封装的E3.S DDR5内存拓展模块,带宽高达54GB/s,延迟低至213.3ns。更强劲的性能可积极助推AI算力、高性能计算和数据中心等领域的处理能力和运算效率的提升。 如果在单机箱内集成8个CXL 2.0 AIC内存扩展卡,就可以形成一个存储池,其容量高达4TB,带宽可达1TB,通过MCIO接口连接服务器,为高性能计算集群提供了前所未有的内存扩展能力。 小结 业界专家普遍认为,AI算法,如深度学习模型,通常需要处理大量的数据集,并且涉及复杂的矩阵运算,内存的带宽和延迟会直接影响到模型训练和推理的速度。尤其是HPC高性能计算任务,如科学模拟、天气预测和生物信息学分析,更需要快速处理和分析大量数据。
CXL 2.0 AIC内存扩展卡的诞生,标志着内存技术的一大飞跃,它不仅解决了现有计算机系统内存性能瓶颈的问题,还提升了计算效率,为AI算力、HPC高性能计算和数据中心等领域的未来发展提供了强有力的技术支持。 |









 闽公网安备 35020302000xxx号
闽公网安备 35020302000xxx号